
Dataset Summary
The Harvard USPTO Dataset (HUPD) is a large-scale, well-structured, and multi-purpose corpus of English-language utility patent applications filed to the United States Patent and Trademark Office (USPTO) between January 2004 and December 2014.
Google Colab Notebooks
You can also use the following Google Colab notebooks to explore HUPD:
1. HUPD Examples: Loading the Dataset.
2. HUPD Examples: Loading HUPD By Using HuggingFace's Libraries.
3. HUPD Examples: Using the HUPD DistilRoBERTa Model.
4. HUPD Examples: Using the HUPD T5-Small Summarization Model.
Usage
Please refer to our GitHub repository or HF Datasets page to learn how to use HUPD with a few lines of code.
Dataset Structure
Each patent application is defined by a distinct JSON file, named after its application number, and includes information about the application and publication numbers, title, decision status, filing and publication dates, primary and secondary classification codes, inventor(s), examiner, attorney, abstract, claims, background, summary, and full description of the proposed invention, among other fields. There are also supplementary variables, such as the small-entity indicator (which denotes whether the applicant is considered to be a small entity by the USPTO) and the foreign-filing indicator (which denotes whether the application was originally filed in a foreign country). In total, there are 34 data fields for each application. A full list of data fields used in the dataset is listed in the next section.
Source Data
HUPD synthesizes multiple data sources from the USPTO: While the full patent application texts were obtained from the USPTO Bulk Data Storage System (Patent Application Data/XML Versions 4.0, 4.1, 4.2, 4.3, 4.4 ICE, as well as Version 1.5) as XML files, the bibliographic filing metadata were obtained from the USPTO Patent Examination Research Dataset (in February, 2021).
Data Shift
A major feature of HUPD is its structure, which allows it to demonstrate the evolution of concepts over time. As we illustrate in the paper, the criteria for patent acceptance evolve over time at different rates, depending on category. We believe this is an important feature of the dataset, not only because of the social scientific questions it raises, but also because it facilitates research on models that can accommodate concept shift in a real-world setting.
Examples and Statistics
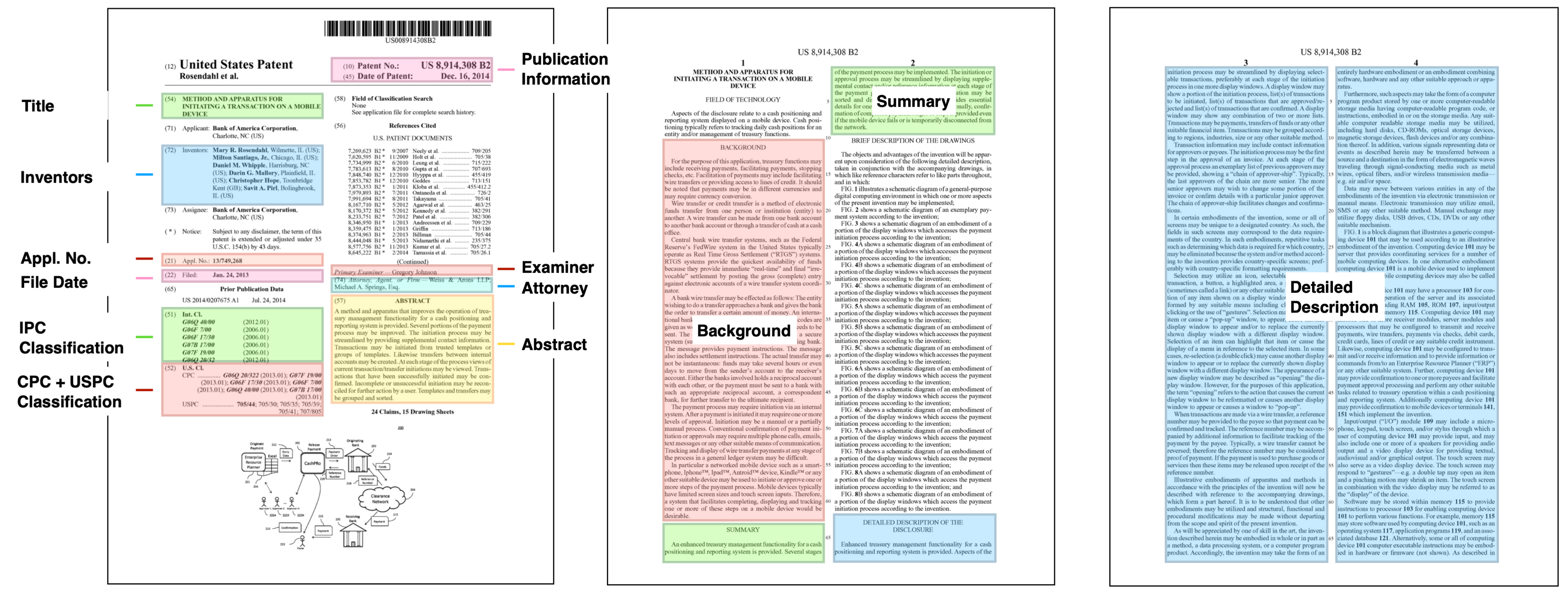
Three pages of the pre-grant version of an example patent document (Method and Apparatus for Initiating a Transaction on a Mobile Device [Publication No: 2014-0207675 A1]). The highlighted sections show a subset of the 34 data fields that we include in the Harvard USPTO Patent dataset.
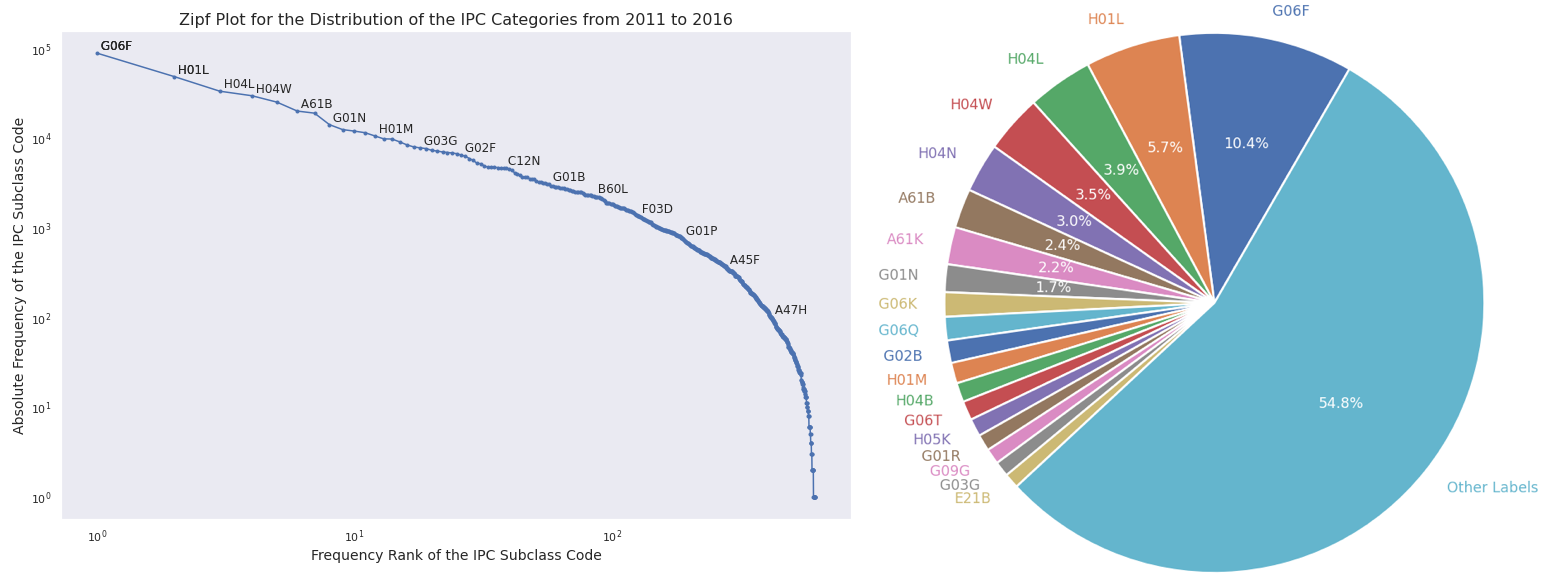
IPC distribution of accepted patent applications from 2011 to 2016 at the IPC subclass level. There are 637 IPC subclass labels in HUPD, of which the most common 20 codes make up half of the distribution. G06F-Electric Digital Data Processing is the largest IPC subclass, accounting for 10.4% of applications.
Licensing Information
HUPD is released under the CreativeCommons Attribution-NonCommercial-ShareAlike 4.0 International.
Citation
If your research makes use of our dataset, models, or findings, please consider citing our paper.
@misc{ suzgun2022hupd,
title={The Harvard USPTO Patent Dataset: A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications},
author={Suzgun, Mirac and Melas-Kyriazi, Luke and Sarkar, Suproteem K. and Kominers, Scott Duke and Shieber, Stuart M.},
year={2022},
publisher={arXiv preprint arXiv:2207.04043},
url={https://arxiv.org/abs/2207.04043},
}▢ Q.E.D.